Docusaurus
Генератор статичных сайтов. Подходит для блогов, документаций, даже лендинг страниц. Не требует своего хостинга, легко редактируется с любого устройства. Работает на Vercel, markdown хранится на GitHub
Plugin/Component Development Notes
Пытался сделать (может и сделал) плагин для отображения обратных ссылок на посты (backlinks). Нашел (issue) готовое (компонент) решение (добавление на doc страницы), но в нем используется внешний предварительных парсер ссылок (process-backlinks.py). Т.е. перед коммитом нужно выполнять сторонний скрипт, который создает backlinks.ts. Я хотел переделать для использования API.
Вот тут еще один чел делал граф, как в обсидиане, что подразумевает тоже сбор ссылок между ресурсами, то он парсил (зачем-то дважды) все markdown файлы в /docs, извлекал с них ссылки и потом строил из созданного .json файлика граф через injectHtmlTags
🎉 Сделал! Ушло 2 дня, миллион нервов и всего пара строк кода.. Настолько изучил Docusaurus, что наверное знаю его теперь лучше, чем некоторые его разработчики.
🥺 Но пришлось костылить. Нет возможности для плагина установить порядок его загрузки, а чтобы не загружать контент постов дважды, нужно дождаться загрузки плагина блога/доков, поэтому пришлось сместиться на несколько хуков выше до postBuild, из-за чего обратные ссылки генерируются только после билда блога, но отсутствуют при yarn run dev.
В ядре Docusaurus параллельно с postBuild всех плагинов выполняется функция проверки сломанных ссылок. Да, это реализовано не в виде плагина, но хуже того – для этой проверки заранее подготовлены и передаются данные, которые можно было передать и в postBuild, но разработчики рашили "вовремя" удалить их из контекста, поэтому пришлось парсить ссылки заново, пробегаясь по контентам регуляркой... Почему регуляркой? Чтобы не лексить файлы с нуля, это уже вообще убого будет. Если пара ссылок пострадает из-за кривого парсинга, то это не критично, но вроде все хорошо.
Хаха, для блог плагина есть поле .content, а для docs уже нет 🤦♂️. Но я так замучился, чт�о просто уже считаю файлы с диска.
Короче в постБилде получаем список постов, парсим регуляркой маркдаун ссылки, сохраняем в файл backlinks.json (todo переделать генерацией на .ts). В компоненте делаем фетч этого файла и делаем с данных блок обратных ссылок.
- На самом деле неожиданно для меня (я впервые в таком веб деве) есть "бекенд", есть "фронтенд". Фронт это когда логи летят в консоль браузера, бэк когда в консоль vscode.
- Я пытался сделать импорт из плагина (бэк) компонента (фронт) и потратил 2 суток, чтобы понять, ЧТО ТАК НЕЛЬЗЯ и это не работает.
- На бэке выполняются плагины. В моем случае
src/plugins/backlinks-plugin.js. - На фронте используются компоненты. В моем случае
src/components/Backlink/index.tsx. - Плагины нужны по сути только ради нескольких хуков:
loadContentгрузит данные дляcontentLoaded(тут content будет undefined, если loadContent не юзался),injectHtmlTags(и еще парочки). В них ты заранее готовишь контент и собираешь всякие данные (для напримерactions.setGlobalData({"some": "shit"});) в отличии от компонентов, в ко�торых ты используешь то, что заранее подготовил (import { usePluginData } from '@docusaurus/useGlobalData'; usePluginData('docusaurus-plugin-backlinks').some). - В компонентах используется то, что заранее заготовлено плагинами. Компонентами можно оверрайдить или инжектиться в блоки на страницах, добавляя например комментарии или возможность эмбединга spotify.
- Встроенный дебаггер NodeJS в VSCode сильно помогал разобраться, что и как работает под капотом у Docusaurus (полный пиздец для меня, который не разбирается в этих ваших вебовских js, ts, react, css, html)
- Я начал с брейкпоинтов в
postBuildотdocusaurus-plugin-sitemapи не понимал почему они не срабатывают. А приyarn run devхук не вызывается. Будь он проклят. Cmd + ,на github открывает vscode в браузере прямо в репе. Там удобнее искать по файлам docusaurus.- localhost:3000/debug – "секретная" ссылка, которая помогает смотреть метаданные и контекст некоторых сущностей при разработке
- Вот тут в docusaurus 2 интересных места: проверка сломанных ссылок (там можно подсмотреть как вообще с роутами все устроено и как оно понимает, что ссылка есть или нет) и рядом выполнение плагинов
- Вот тут я и сам немного запутался, но я так и не запомнил структуру контекста в разных местах. #todo написать шпаргалку для контекста плагина, компонентов и т.д.
- У плагина блога есть теоретически полезная функция для сбора ссылок с поста:
processBlogPosts - Есть незадокументированная env
DOCUSAURUS_PERF_LOGGER=true, которая добавляет некоторые дополнтельные логи - Это стоило мне с десяток-второй часов жизни. Команда
yarn run docusaurus clearочищает кеши и прочие build артефакты. У меня закешировался js файл с ошибкой и я все на свете перепробовал, чтобы ее исправить. Пока не почистил артефакты... - В конце концов минимально без оверлоада для разработки плагина нужно 2 терминала. В одном
docusaurus dev, в другомtsc build --watch. При изменении ts файлов сразу будет билдится js версия и применяться в браузере докусарусом. Ну иyarn linkдля использования локального пакета, а не пушить и пуллить с npmjs репа при каждом изменении.
Получение данных плагинов в компонентах
Данные записываются в хуке contentLoaded({content, actions}) через НАПРИМЕР actions.setGlobalData({"some": "shit"}). Есть и другие варианты, например запись в json (предпочтительно для больших данных).
Получить данные в компонентах есть 3 основные функции:
import { usePluginData, useAllPluginInstancesData } from '@docusaurus/useGlobalData';
import useGlobalData from "@docusaurus/useGlobalData"
-
В
useGlobalData()там примерноdata['docusaurus-plugin-backlinks'] = {default: {some: 'shit'}}и та�к для каждого плагина. Яндекс метрика, беклинкс, контент-докс. Поле default есть у каждого плагина. Под ним и хранятся данные. -
useAllPluginInstancesData('docusaurus-plugin-backlinks')возвращает{default: {some: 'shit'}}. Не знаю зачем делать было отдельную функцию. По сути этоuseGlobalData()['docusaurus-plugin-backlinks'] -
usePluginData('docusaurus-plugin-backlinks')> сразу{some: 'shit'}
Шпаргалка по контекстам и т.п.
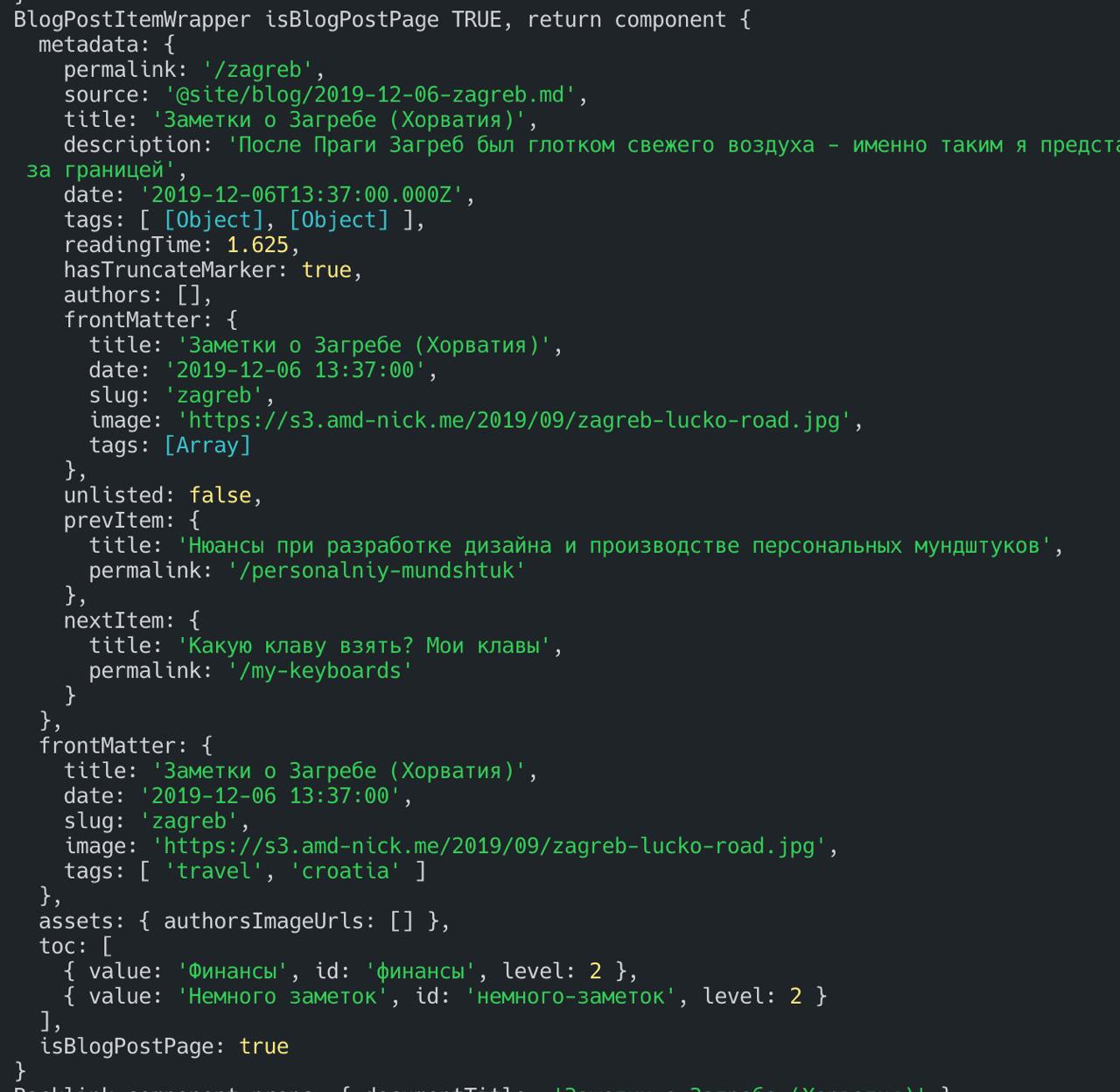 –
– useBlogPost() в src/theme/BlogPostItem.js при оверрайде компонента блог поста
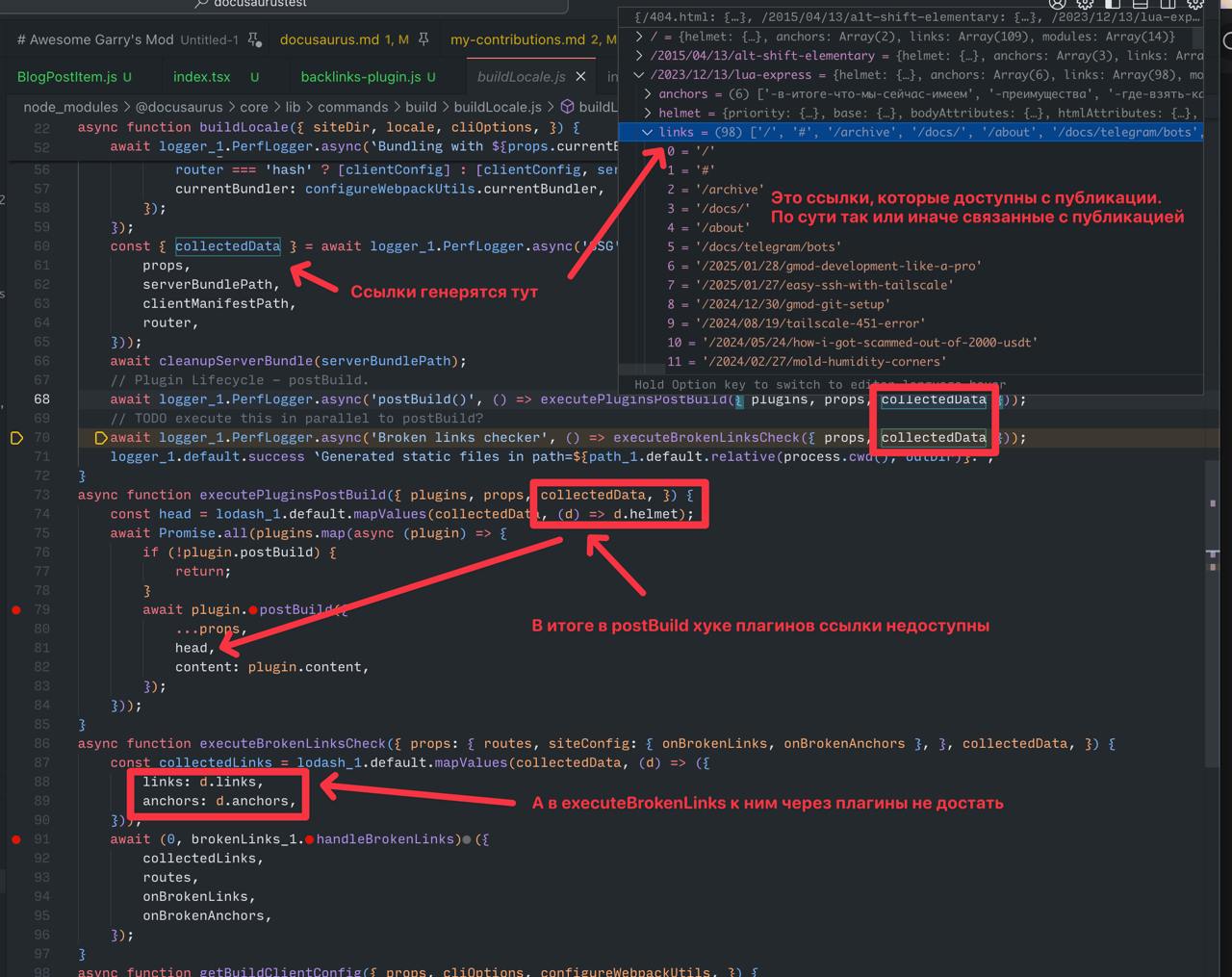 – причина, почему так сложно с относительными ссылками: в
– причина, почему так сложно с относительными ссылками: в node_modules/@docusaurus/core/lib/commands/build/buildLocale.js просто убрали связанные ссылки перед вызовом хуков postBuild плагинов
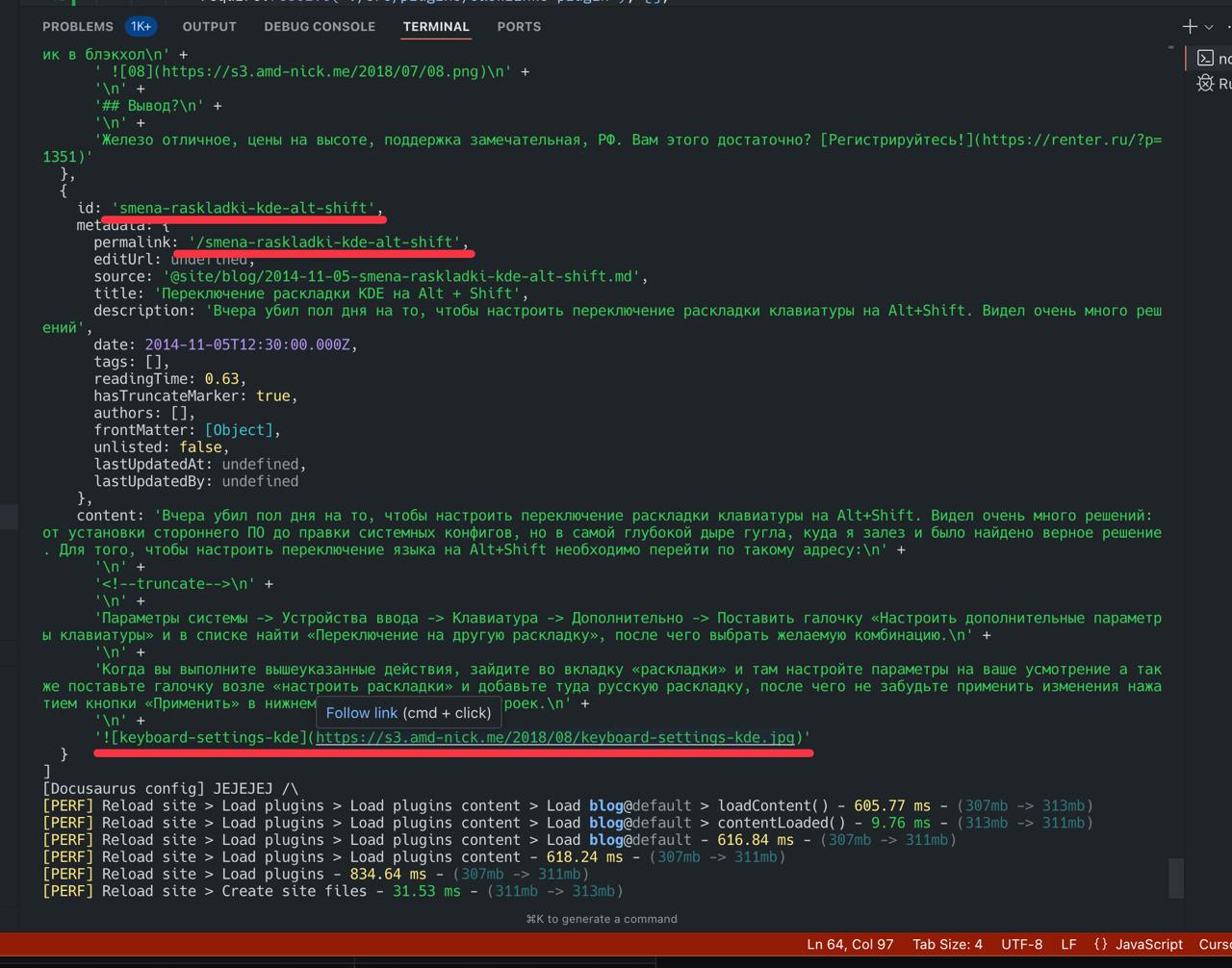 –
– processBlogPosts({blogPosts}) в docusaurus.config.js. Выполняется в loadContent хуке плагина блога.
 –
– postBuild(props) самодельного плагина. Много интересного (роуты, исходники постов в .md, полностью загруженные данные всех плагинов, siteDir, siteConfig и т.д.)
Полезно знать
- Контент при клике на категорию определяется в файле с
{folder_name}/{folder_name}.md - Если файл начинается с header 1, то он определяет название страницы
- При переходе на typesense билд увеличился где-то на 10-20 сек. Думаю, фиксится удалением algolia из пакетов
- Algolia подтверждала заявку на подключение к ним где-то месяц
- Для замены стандартной index страницы вроде в static удалил папку pages
- Стиль этого сайта писал не я, а взял с другого. Искал стили через гитхаб поиск вот так:
path:/src/css/custom.css --ifm-font-family-base - Поддержка дополнительных подсветок синтаксисов
 – не делайте картинку с дескрипшином первой строкой после h1 заголовка. Оно возьмет описание картинки как описание поста, испортив его SEO.
– не делайте картинку с дескрипшином первой строкой после h1 заголовка. Оно возьмет описание картинки как описание поста, испортив его SEO.
Перенос с Ghost
Причины перехода с Ghost: клик
- Чтобы ссылки с Ghost продолжили работать, нужно было blog поместить на /. Делается через routeBasePath = "/" для presets.blog в конфиге. Без этого ссылки были в site.com/blog/slug
- В каждом посте сверху файла есть front-matter блок, где в каждом указан slug со старого блога
- Посты с Ghost экспортировал в Markdown через эту тулзу
- Посты были экспортированы с неправильной датой. Пришлось добавлять +3 часа через самописный мини-скрипт (или вручную)
- Во многих постах были огрызки HTML. Их пришлось вручную заменять на markdown (Ctrl + F >
<figure,<!--kg-card-begin,<!--kg-card-end) - Вручную нужно было искать и заменять
__GHOST_URL__на правильные ссылки - Docusaurus впервые в репе деплоился через vercel, но он установил устаревшую версию
Markdown заметки
Выделение строк кода
### This
## Is
# Markdown
---
fux
Admonitions
Some content with markdown syntax. Check this api.
Some content with markdown syntax. Check this api.
Some content with markdown syntax. Check this api.
Some content with markdown syntax. Check this api.
Some content with markdown syntax. Check this api.